Polish Open Source

I resurrected my old polish-github-rank project. Polish Open Source is not just a ranking of Polish open source contributors. It also helps them get to know each other.
This will be my monument.
Software engineering notes, projects, experiments, and tools by Maciej Ciemborowicz.
I resurrected my old polish-github-rank project. Polish Open Source is not just a ranking of Polish open source contributors. It also helps them get to know each other.

A practical index of ideas from thirteen well-known software engineering books translated into rule files for AI coding agents. It covers implementation, review, refactoring, testing, documentation, legacy code, production systems, data systems, and domain modeling. The point is not to replace reading the books, but to make their recurring habits easier to use during everyday work in Codex, Cursor, and Claude Code. The article links to the repository, explains the supported formats, and shows how to choose between a broad default rule set and focused rules for specific engineering tasks.

A small winter hardware project built around an old cast iron stove found in the basement and a Raspberry Pi 2 that needed a purpose. The stove could no longer be used for burning wood, but it could still become something warm: a lamp with bulbs, relays, controls, ambient soundscapes, and internet radio. The article is mostly a visual record of the build, with photos of the restored object and a component list for the electronics inside. It is part nostalgia for crackling wood, part reuse project, and part tiny domestic installation.

Notes from using GPT-4 intensively as a programming assistant while building a small Python project outside the author's usual stack. The article argues that the valuable work shifts toward asking precise questions, shaping architecture, naming things well, reducing coupling, and keeping modules small enough for the model to reason about. It also describes why memory limits matter in practice and why generated code still needs verification from someone with engineering judgment. The conclusion is deliberately cautious: GPT-4 can implement a lot, but it does not know the whole project and does not replace responsibility for design.

A practical write-up about a very specific kind of CI pain: acceptance tests that became faster after switching Cucumber from Selenium to Poltergeist, but started failing randomly when PhantomJS crashed on CircleCI. The article walks through recording failed scenarios with Cucumber's rerun formatter, running only those scenarios again, and adapting the approach for Knapsack and parallel CI nodes. It also calls out the tradeoff clearly: reruns can reduce noise, but they can also hide real intermittent bugs if you stop paying attention.
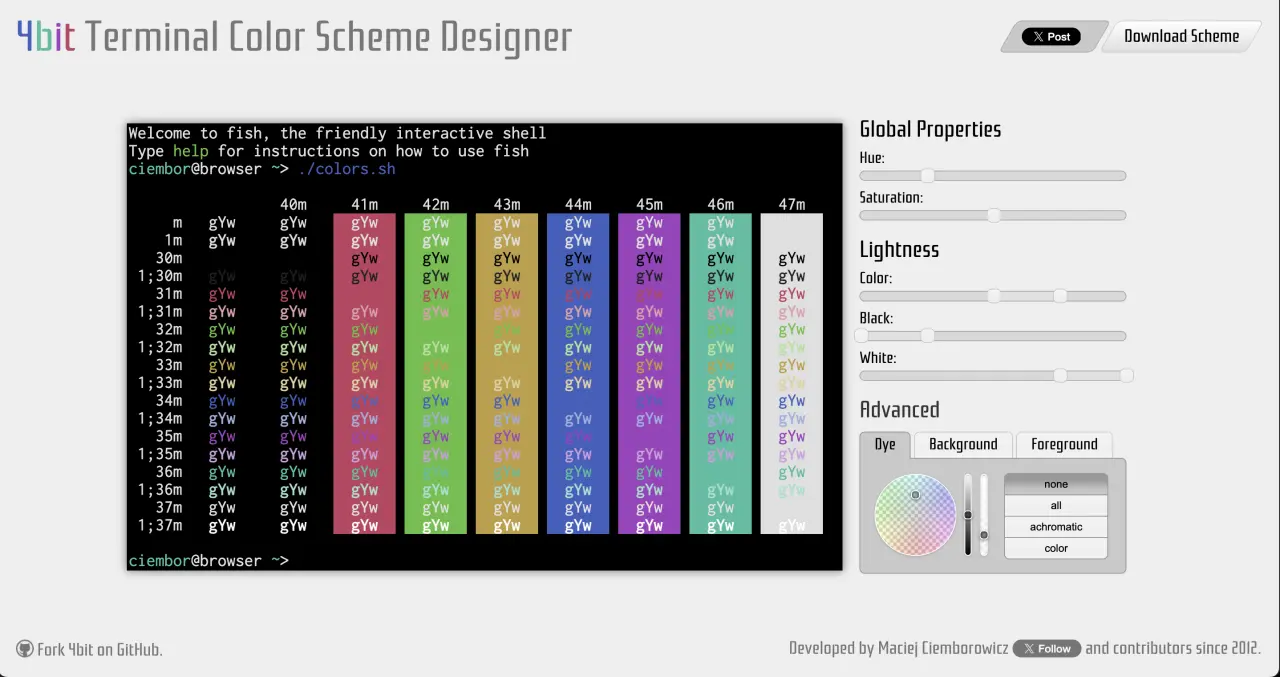
A browser-based tool for creating consistent terminal color schemes without needing to understand color theory first. The article explains what 4bit does, how the palette controls work, and why exporting to many terminal formats mattered for the project. It also gathers the most interesting bits of reception: Hacker News, Reddit, Wykop, Mintty, Gogh, and terminal.sexy. This is less a changelog and more a short archive of a tool that kept travelling through terminal communities long after its first release.