What To Focus On When Programming With Gpt4?
I spent the last month intensively testing the capabilities of the Generative Pre-trained Transformer in the aspect of programming. I asked myself — can I create a customized Spotify client using Ctrl+C / Ctrl+V, tailored to my whims (a radio alarm clock with Discover Weekly based on a RaspberryPi and a ’60s tube radio definitely is one). With GPT4, this is possible. Currently, the project has 1485 lines of Python code in 70 files. It’s worth adding that I don’t normally program in Python. Does this mean that anyone can be a programmer? At the moment, the answer is — no.

Architecture and Engineering
The skill that will be key in the upcoming era of AI is asking the right questions. Crucial for that handful of people who will still work intellectually. Asking the right questions, leading the shortest way to achieve a specific goal, still requires intelligence and knowledge gained through experience. In the context of programming, it’s not so much knowledge of the language and library interfaces, but general knowledge of architecture/engineering software, the environment we work in, and intuition.
Memory…
To effectively program with GPT4, you need to be aware of its limitations. Human memory can be divided into several types:
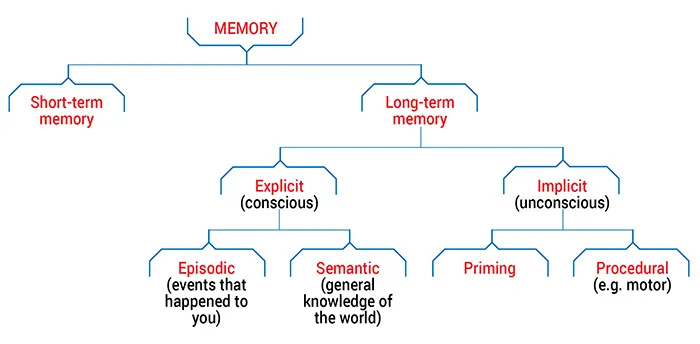
From long-term memory, GPT4 has semantic memory (language model) and short-term — session, which consists of tokens. GPT does not expand its general knowledge and does not remember its experiences (lack of episodic memory, only knowledge of “what”, “where” and “when” until the model is trained). GPT4 can handle a maximum of 4096 tokens in one session. It’s hard to “eyeball” exactly how many tokens a piece of code has*, a token can be a single character (parenthesis, comma, or even whitespace), it can be a variable name, but the variable name itself can also consist of several tokens. In practice, GPT4 turns out to be very good at handling Python code that has several hundred lines of code (the less, the better), but it doesn’t know the entire project. Therefore, the basic principle that one must impose on oneself is decoupling in all its forms and at every level of the project.
- Single Responsibility Principle — One class/function/method should serve only one purpose. Without this assumption, at some point, our code will not fit in the session. Break up blocks and functions, create private methods, then move them to new classes.
- Modularization — We should strive to ensure that the entire module that the transformer is able to process (along with our query/instruction) fits into the session. Avoid monolithic applications. Create modules and libraries with a simple interface so that it’s easy to define the data passed to the function and the return value. Microservices can also be a solution. GPT doesn’t know the entire relational database and all models.
- Avoiding Global State — In my project, I allowed myself to create a Singleton with configuration, but it’s worth stopping at such actions.
- DRY? — yes and no. It is important to maintain low code complexity and readability. DRY allows creating concise code that will fit in the session, but GPT will not know all parts of the system that use it.
- Very important is also clear and unambiguous naming of variables, classes, and functions. I would avoid writing comments — they take up valuable space, and the code should be understandable regardless of whether they are there or not. GPT tends to produce comments, it’s worth deleting them and writing self-commenting code.
- Metaprogramming? — and here, as in the case of DRY, I have objections. Metaprogramming allows shortening many repetitive parts of the code, but makes it less readable and MUCH more difficult to debug.
Summary
GPT4 still does not replace a programmer. However, it successfully copes with implementation. Its main limitation is the lack of knowledge of a broader context. GPT4 does not learn; it already knows a lot, but it does not know our project. We must ask proper, well-defined questions. We must verify each answer based on our experience and intuition, define parameters, expected output and dependencies, as long as they are not public. We need to think about whether the received code meets our expectations in terms of functionality and code quality. We must take care of the architecture and refactoring ourselves. We need to look for edge cases and scrutinize everything to get what we want from it.
By the way, this article is written in Polish. It was translated by GPT4 with no corrections. At least it was written by me. I’m unsure what fate awaits programmers when AI acquires episodic memory and the ability to learn on the fly. I’m asking myself what alternative job positions will be available for us… if we like to think, it may turn out that it will no longer be needed by society.
* to accurately count the number of tokens, you can use the transformers library from Hugging Face.